Intro to assembler
5 Jul 2021
This blog entry is a gentle introduction to assembler that can set you up to read more involved books.
I dive straight into writing little assembly programs, using tools that are available and common on Linux.
I've tried to focus each section on a tiny concept that is illustrated by a little working program.
Limits and Assumptions
This book focuses only on Intel 64-bit assembler on Linux.
This book uses AT&T assembler syntax, because that's the default for a lot of tooling on Linux, including, for instance, decompiled C code.
This book assumes a few things about your knowledge:
- You have programmed in other programming languages before, and you have at least dabbled with the C programming language.
- You have at least passing familiarity with the ways numbers can be represented. That is, decimal 42 can be representd as 2A in hexadecimal or 101010 in binary.
- You are comfortable with the Linux command line.
- You have a favorite text editor and are comfortable writing code with it.
The command-line examples all use vim, but when you see
vimjust subtitute your favorite editor.
A First Assembler Program
Let's assume we are running Ubuntu and that we want to be sure the GNU Assembler is installed.
Just do this:
$ sudo apt install binutils
Now, let's be sure the assembler and the linker are in the path:
$ which as /usr/bin/as $ which ld /usr/bin/ld
Excellent! We are ready to write assembler.
If you are using some other Linux distribution, you may have to use yum or some other package manager to get (or see if you already have) the GNU binutils installed.
Assembler is so low-level that even Hello World is too big an effort for a first program. It's much easier to write a simple program that returns a non-zero return value. Other entry-level assembler books also encourage writing a return-non-zero program as a first exercise, so I'm just following in their footsteps.
Illustration of Return Value
If you run a program at the shell, when the program exits, it leaves a
return value in a special shell variable called $?. Let's see it in action.
There are two binaries on most systems named true and false, which
return 0 and 1 respectively.
$ true $ echo $? 0 $ false $ echo $? 1
This can be done from a bash script, like so:
$ vim my_bash_script.sh
#!/bin/bash echo "I will return 42" exit 42
$ chmod +x my_bash_script.sh $ ./my_bash_script.sh I will return 42 $ echo $? 42
And, of course, this can be done from C, the language that
true and false are written in:
$ vim my_c_program.c
#include <stdio.h>
int main() {
printf("I will return 42\n");
return 42;
}
$ gcc my_c_program.c -o my_c_program $ ./my_c_program I will return 42 $ echo $? 42
So now let's do the same thing in assembly, minus the echoing of "I will return 42", because printing things in assembly is tricky enough that we will avoid doing that for now.
Assembly source code files (on Linux) end with .s, so let's make a file
named my_exit.s.
$ vim my_exit.s
Type this into my_exit.s (I will explain every line later):
.section .text .globl _start _start: movq $60, %rax movq $42, %rdi syscall
Now let's compile and link our program:
as my_exit.s -o my_exit.o ld my_exit.o -o my_exit
Let's run our freshly-compiled program, and check that its exit value was 42:
$ ./my_exit $ echo $? 42
Nice! We just wrote an assembler program that returns an exit value of 42.
What does each line of our program do?
Here is the first line:
.section .text
It tells the assembler that the instructions that follow need to go in the text section of the ELF file, which is where the actual program instructions go. ELF files have more than one section (for instance, there is a data section for initialized global data) but we only need the .text section of the ELF file for this program.
Let's skip to the third line (we will return to line 2 in a moment):
_start:
This actually labels the memory address where the following item (in this
case, the movq instruction on line 4) will be loaded.
_start: is a special label, because by convention, when you run an
ELF binary, the Linux kernel goes
to the memory address at that label and starts executing code there.
Let's bounce back to the second line:
.globl _start
This is a directive to the assembler to tell it that the _start: label
is visible to the outside world (so that the Linux kernel can find it when
it starts the program). In longer programs, labels mark adresses to jump to,
but those labels need not be exposed to the outside world; they are only
interesting to the program itself. So those sorts of labels are not marked
with .globl.
Now let's look at line 4. It's an actual instruction for your Intel CPU!
movq $60, %rax
It says "move the integer 60 into the register named rax". Notice how
in GNU assembler (with its AT&T syntax) literals begin with a
dollar $ sign, and register names begin with
a percent % sign.
Register?
If you've never programmed assembler before, this may be your first exposure to registers. Higher-level languages like C make it seem like all of your variables exist in some uniform array of memory, and are operated on in that memory space.
The truth turns out to be more complicated. Usually a value has to be fetched from memory and placed into a register on the CPU. An instruction is called that operates on the value in that register, likely changing it, and then the contents of that register are moved back out into RAM.
Of course, it's only fair to ask "Why aren't CPUs designed to just directly change values in RAM?" Apparently, it is easier to design CPUs whose that only get/set values in RAM. The actual transformation of data only happens in registers on the CPU itself.
OK, we now have the decimal number 60 in the %rax register. Why?
That will be explained shortly.
Time for line 5!
movq $42, %rdi
Very similar to line 4! Move the decimal value 42 into the %rdi
register. Again, the why of this will be explained shortly.
Line 6!
syscall
syscall is well named, because it's asking your Linux kernel to do
some work via a system call.
System Calls
But what is a Linux system call? A Linux system call is a service that the kernel makes available to a program. For instance, Linux system call 1 (yes, they all have numbers!) writes bytes to a file descriptor.
The number for every Linux system call can be seen right in the Linux source code, in the file
arch/x86/entry/syscalls/syscall_64.tblalthough this web site has a really nicely formatted table of Linux's system calls.
The Linux kernel has a convention for making system calls. The number of the system call itself must go in register
%rax. A system call can have from 0 to 6 arguments, and those arguments need to go into these registers in this order:%rdi, %rsi, %rdx, %r10, %r8, %r9There are no system calls with 7 or more arguments.
Syscalls can only have one return value, and that return value goes into the
%raxregister. Yes, the register we use to identify a syscall is overwritten with that syscall's return value!
System call number 60 is the exit system call, and that's why
we put the value 60 into the %rax register in line 4 of
our program.
We want to return 42 as our exit code. The exit system call takes
one argument. The first syscall argument goes in register %rdi,
so that's why we put the literal value 42 into %rdi on line 5.
So let's look at the three actual instructions of our little program again:
movq $60, %rax movq $42, %rdi syscall
We have to set up one register with our syscall number, another with that syscall's only argument, and then (and only then!) do we call the actual syscall instruction.
So that's a taste of assembly programming. We just successfully asked the Linux kernel to exit our program and have it return 42 as its exit value.
Following a Program with the gdb Debugger
A debugger can help us learn assembler faster, because it allows us to step through our programs and see the contents of CPU registers as we go.
Let's install gdb.
$ sudo apt install gdb
With that out of the way, let's recompile our program from above with debugging info in it, so that the program is easier to debug.
as --gstabs my_exit.s -o my_exit.o ld my_exit.o -o my_exit
From now on, we are always going to compile using --gstabs, so that we
can debug any of our programs whenever we want.
Let's debug our program from above. Make sure you are in the same
directory as the my_exit binary, and run this (the
-q option just "quiets" gdb's startup messages):
$ gdb -q ./my_exit
Our program is not yet running, but we have opened it with gdb. Before we run our program, we need to set a breakpoint. gdb will stop at this breakpoint, and from there we can step through the program and look at values in registers.
Let's set a breakpoint at the label _start.
(gdb) break _start Breakpoint 1 at 0x400078
Now we can run our program, and the debugger will stop execution at _start!
(gdb) run Starting program: /home/mwood/linux_amd64_adm/chap_02/my_exit Breakpoint 1, _start () at my_exit.s:4 4 movq $60, %rax
We are at the first line of our program, and this is before it
gets executed. We can ask to see what's in our %rax register,
using gdb's info registers command.
(gdb) info registers rax rax 0x0 0
Note that we don't refer to %rax as %rax in gdb: we omit the
percent sign and just call it rax.
Also, we can use gdb's printf command to show the contents of %rax,
this time referring to $rax with a dollar sign:
(gdb) printf "rax: %lld\n", $rax rax: 0
The printf command is very useful. It requires you to know about
printf and its formatting patterns, but most languages have some
version of printf because it's such a useful thing.
The one downside of printf is that it doesn't have a nice binary
printing mode, whereas gdb's print command does. Here, we will
print the contents of the %rax register in binary:
(gdb) print/t $rax $1 = 0
Again, notice how we refer to %rax as $rax with a dollar sign
instead of a percent sign for gdb.
With all of this printing, we have certainly determined that
the number 60 isn't in the %rax register yet.
Now let's run that line of our program.
(gdb) next 5 movq $42, %rdi
gdb shows us the next line of our program, which has not run yet, but our
previous line has, so now let's go look at the %rax register.
(gdb) info registers rax rax 0x3c 60 (gdb) print/t $rax $2 = 111100 (gdb) printf "rax: %lld %#llx %#llo\n", $rax, $rax, $rax rax: 60 0x3c 074
And there's our number 60, waiting in %rax. We showed it three ways:
as decimal (d),
as hex (x), and
as octal (o).
Let's advance one more line, and then check what's in the %rdi register.
(gdb) next 6 syscall
Remember that syscall hasn't run yet; but we have run the line that
puts 42 into register %rdi:
(gdb) info registers rdi rdi 0x2a 42 (gdb) printf "rdi: %lld %#llx %#llo\n", $rdi, $rdi, $rdi rdi: 42 0x2a 052 (gdb) print/t $rdi $3 = 101010
Let's execute the next (and final) line of our program:
(gdb) next [Inferior 1 (process 2615) exited with code 052]
gdb tells us the process exited with the exit code 052 in octal notation, which is 42 in binary.
We can quit gdb like so:
(gdb) quit
Detour: Registers And Why So Many Commands End with "q"
Skip this section if you already know about the different sorts of registers on Intel CPUs.
I want to keep this little aside on registers brief, so that we can get back to coding.
This tour of registers will be short and incomplete; after all, this is only an introduction, not a reference!
If you want to know everything about x86 registers, there are always more complete references, not to mention Wikipedia.
It's fascinating how processor evolution is a bit like the evolution of a city! Newer things get built on top of older things.
For the registers I want to cover in this book, here's what they looked like when Intel processors were 16-bit processors, like with the 80286 CPU:

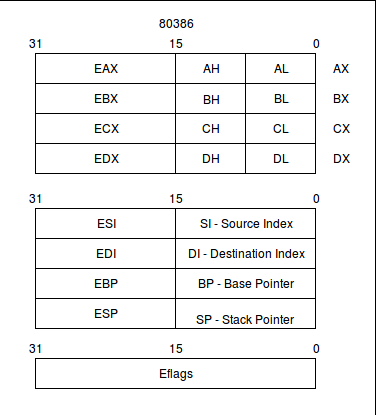
Here's what registers looked like around the time of the 80386, with the bump to 32-bit computing:
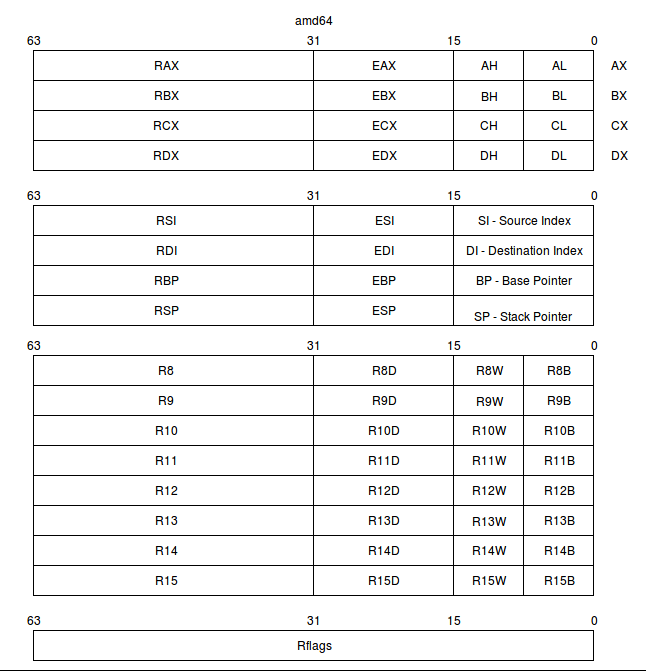
And here's what just the basic registers look like on 64-bit Intel CPUs:
One thing to note is that even on brand new 64-bit Intel CPUs, 8-, 16-, and 32-bit regisers from the old models are all still there!
A small note on reading the diagrams:
Most of the register names, reading from left-to-right, encompass the smaller register to its right. So the R8 register is not bits 31 through 63; it's bits 0 through 63, swallowing up R8D, R8W, and R8B.
R8D is bits 0 through 31, swallowing up R8W and R8B.
R8W is bits 0 through 15, swallowing up R8B.
R8B is bits 0 through 7.
There is an exception to this rule: The older 16-bit AX, BX, CX, and DX registers are labelled off to the side, because both the high and low bytes of those registers can be accessed! For instance, AH acesses bits 8 through 15 of AX, while AL accesses bits 0 through 7 of AX.
As CPUs have evolved, registers have become more general purpose. Whereas the newest register names are simply R8 through R15, the older register names reveal their special purposes. We will see that history asserting itself as we use some of the assembler instructions that need operands to be in certain registers (always the older ones with the more specific-sounding names), or that leave the results of operations in certain registers.
It is interesting to see some of the naming choices. Presumably the older AH and AL registers' 'H' and 'L' letters must mean "high" and "low" bytes. The new R series of registers' suffixes of 'D', 'W', and 'B' probably mean 'double', 'word', and 'byte', respectively. The 'E' prefix of 32-bit registers is said to be "extended" in online documents.
Finally, let's not forget the flags register!
The pictures show how the flags register has grown from 16 bits to 32 to 64, changing its name from Flags to Eflags to Rflags along the way, but that's not the interesting part.
What makes Rflags interesting is that it is a special-purpose register where every bit has a meaning. Not all bits will be explained here, but in later sections, we will look at bit at bit 11 (OF), which will tell us whether or not an addition has overflowed.
TODO: show accessing the smaller registers and larger registers and the 'q' and 'l' and 'b' versions of commands.
How to Add Two Numbers
We can continue to use the return status from the process as the output of other operations. Let's add two numbers.
$ vim add.s
.section .text .globl _start _start: movq $4, %rbx movq $3, %rdi addq %rbx, %rdi movq $60, %rax syscall
Here's how this works:
- We put the number 4 in the
rbxregister. - We put the number 3 in the
rdiregister. - We add the contents of the
rbxregister to the contents of therdiregister.
From there on, it's just like our exit-with-value-42 program: our new
sum is sitting in the rdi register, which is the first argument of the
exit syscall. We put 60 in rax to indicate that we want to call the exit
syscall (system call number 60) and then we actually use the syscall
instruction and exit, leaving our sum as the exit value of our program.
$ as --gstabs add.s -o add.o $ ld add.o -o add $ ./add $ echo $? 7
The interesting thing about this is that in higher level languages, one would normally expect to see addition work like this:
a = 4 b = 3 c = a + b
But as you can see, in assembler, it's a bit different. It's more like
a = 4 b = 3 b += a
The interesting thing about assembler is that we are much more at the mercy of the designers of the CPU: the designers decided that the add instruction would clobber the second register argument with the sum, so that's how it works for us in assembler!
The Flags Register
Something we all know about integer addition on computers is wraparound. If we take a 64 bit signed integer with all bits set, it's the maximum value that can be held: 9,223,372,036,854,775,807. But if we add 1 to it, The number will wrap around and become -9,223,372,036,854,775,808.
Fun fact: there's a register on Intel CPUs called the rflags register
that tells us when this happens. (Note, however, that in gdb, we
have to ask about the 32-bit eflags register, not the
64-bit rflags register.
Let's take a look at this using the following program:
$ vim add.s
.section .text .globl _start _start: movq $9223372036854775806, %rdi addq $1, %rdi addq $1, %rdi addq $1, %rdi movq $60, %rax syscall
Now let's follow this through in the debugger.
$ as --gstabs add.s -o add.o $ ld add.o -o add $ gdb -q ./add (gdb) break _start Breakpoint 1 at 0x400078: file add.s, line 4. (gdb) run Starting program: /home/mwood/linux_amd64_adm/chap_05/add Breakpoint 1, _start () at add.s:4 4 movq $9223372036854775806, %rdi (gdb) info registers rdi rdi 0x0 0 (gdb) info registers eflags eflags 0x202 [ IF ] (gdb) next 5 addq $1, %rdi (gdb) info registers rdi rdi 0x7ffffffffffffffe 9223372036854775806 (gdb) info registers eflags eflags 0x202 [ IF ] (gdb) next 6 addq $1, %rdi (gdb) info registers rdi rdi 0x7fffffffffffffff 9223372036854775807 (gdb) info registers eflags eflags 0x206 [ PF IF ] (gdb) next 7 addq $1, %rdi (gdb) info registers rdi rdi 0x8000000000000000 -9223372036854775808 (gdb) info registers eflags eflags 0xa96 [ PF AF SF IF OF ] (gdb) next 8 movq $60, %rax (gdb) next 9 syscall (gdb) next [Inferior 1 (process 11217) exited with code 01] (gdb) quit
gdb knows about the eflags register, so it prints out the two-letter
acronyms of the flags that are set in the register when we say
info registers eflags. Handy!
Let's not get bogged down with the meaning of every flag, but note there is a flag called OF (for overflow) that gets set when our addition wraps the value around to a negative.
It's interesting that most higher-level programming languages do not surface this feature.
How to Multiply
Multiplication is another interesting look at how an Intel processor
works. One number that you are multiplying by has to be in the
rax (a stands for accumulator?) register.
The other number can be in any other register of your choosing,
but that other number cannot be a literal!
Even more interesting is that the results of the multiplication can end
up in two regisers, not one. When multiplying two 64 bit numbers, the result
could potentially be a 128-bit number. Intel CPUs actually respect this by
producing a 128-bit number when two 64-bit numbers are multiplied.
For the 128-bit result of a multiplication, the high bits will be found in
the rdx register, and the low bits
are in the rax register.
Let's see that in action.
$ vim mul.s
.section .text .globl _start _start: movq $18446744073709551615, %rax movq $2, %rcx mulq %rcx movq $0, %rdi movq $60, %rax syscall
$ as --gstabs mul.s -o mul.o $ ld mul.o -o mul $ gdb -q ./mul
(gdb) break _start Breakpoint 1 at 0x400078: file mul.s, line 4. (gdb) run Starting program: /home/mwood/linux_amd64_adm/chap_06/mul Breakpoint 1, _start () at mul.s:4 4 movq $18446744073709551615, %rax (gdb) printf "%llu %llu %llu\n", $rcx, $rdx, $rax 0 0 0 (gdb) next 5 movq $2, %rcx (gdb) printf "%llu %llu %llu\n", $rcx, $rdx, $rax 0 0 18446744073709551615 (gdb) next 6 mulq %rcx (gdb) printf "%llu %llu %llu\n", $rcx, $rdx, $rax 2 0 18446744073709551615 (gdb) next 7 movq $0, %rdi (gdb) printf "%llu %llu %llu\n", $rcx, $rdx, $rax 2 1 18446744073709551614 (gdb) printf "%llx %llx %llx\n", $rcx, $rdx, $rax 2 1 fffffffffffffffe
As we can see here, when we put the max unsigned 64 bit int value into
rax and multiply it by the number 2 in register rcx,
the number 1 ends up in
the rdx register; the overflow bit from multiplying what's in the
rax
register. In fact, notice how the contents of rdx and rax
make no sense
when shown as decimal numbers; we have to go to hexidecimal representation,
because the product is really 1fffffffffffffffe.
It's interesting how from the point of view of the CPU, the registers just hold bits. There are no real types like we would find in other langages. The bits in a register are treated as an unsigned integer because we used mulq; imulq would just as happily have treated the bits as a signed int.
Because of this state of affairs, gdb's printf command
can be useful to
show the bits of registers in different ways. If we had just used
info registers, the values would have been shown as
hex and signed decimal.
Let's look at how the imul command behaves.
$ vim imul.s
.section .text .globl _start _start: movq $-9223372036854775808, %rax movq $2, %rcx imulq %rcx movq $0, %rdi movq $60, %rax syscall
$ as --gstabs imul.s -o imul.o $ ld imul.o -o imul $ gdb -q ./imul
(gdb) break _start Breakpoint 1 at 0x400078: file imul.s, line 4. (gdb) run Starting program: /home/mwood/linux_amd64_adm/chap_06/imul Breakpoint 1, _start () at imul.s:4 4 movq $-9223372036854775808, %rax (gdb) next 5 movq $2, %rcx (gdb) printf "%lld %lld %lld\n", $rcx, $rdx, $rax 0 0 -9223372036854775808 (gdb) printf "%llx %llx %llx\n", $rcx, $rdx, $rax 0 0 8000000000000000 (gdb) next 6 imulq %rcx (gdb) printf "%lld %lld %lld\n", $rcx, $rdx, $rax 2 0 -9223372036854775808 (gdb) next 7 movq $0, %rdi (gdb) printf "%lld %lld %lld\n", $rcx, $rdx, $rax 2 -1 0 (gdb) printf "%llx %llx %llx\n", $rcx, $rdx, $rax 2 ffffffffffffffff 0
Although one would expect imul to do the sign extension properly, it's
still cool to see: The hex number 8000000000000000 has only the highest bit
set, making it the minimum signed 64-bit integer, but multiplying it by 2
simply turns it into a 128-bit negative number of
ffffffffffffffff0000000000000000.
How to Divide
When you do integer division on Intel CPUs, the dividend is assumed to be a 128-bit number
where the high bits need to be in the rdx register, and
the low bits need to be in the rax register,
pretty much the inverse of multiplication!
Also like multiplication, the other number
(in this case the divisor) can be in a register of your choosing, but
cannot be a literal.
When you divide, the quotient ends up in the rax register, and the remainder
ends up in the rdx register.
Let's take a look!
$ vim div.s
.section .text .globl _start _start: # for 19 / 5 ... movq $0, %rdx # dividend high bits are all zero for our number movq $19, %rax # dividend low bits are the number 19 movq $5, %rcx # 5 is the divisor divq %rcx movq $0, %rdi movq $60, %rax syscall
(gdb) break _start Breakpoint 1 at 0x401000: file div.s, line 6. (gdb) run Starting program: /home/mwood/tmp2/div Breakpoint 1, _start () at div.s:6 6 movq $0, %rdx # dividend high bits are all zero for our number (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=0 (gdb) next 7 movq $19, %rax # dividend low bits are the number 19 (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=0 (gdb) next 8 movq $5, %rcx # 5 is the divisor (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=19 (gdb) next 9 divq %rcx (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=5 rdx=0 rax=19 (gdb) next 11 movq $0, %rdi (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=5 rdx=4 rax=3
This must mean that / and % in languages like C
must both use the same div instruction on the CPU!
Let's do division and modulus in a C program and decompile it to see which assembly instructions get used.
$ vim cdiv.c
int main() {
unsigned long long dividend = 19;
unsigned long long divisor = 5;
unsigned long long quotient = 0;
unsigned long long remainder = 0;
quotient = dividend / divisor;
remainder = dividend % divisor;
return 0;
}
$ gcc -S cdiv.c $ cat cdiv.s
... some code omitted here ... movq $19, -32(%rbp) movq $5, -24(%rbp) movq $0, -16(%rbp) movq $0, -8(%rbp) movq -32(%rbp), %rax movl $0, %edx divq -24(%rbp) movq %rax, -16(%rbp) movq -32(%rbp), %rax movl $0, %edx divq -24(%rbp) movq %rdx, -8(%rbp) ... some code omitted here ...
The short answer is, yes! The C programming language uses div for both division and modulus; it just uses the quotient or remainder register to get the answer for either operation. (The funny looking `-24(%rbp)` code will be explained later, but the quick explanation is that's how assembler refers to local variables on the stack.)
What happens when we divide by zero? Here's a program:
$ vim divz.s
.section .text .globl _start _start: movq $0, %rdx movq $19, %rax movq $0, %rcx divq %rcx movq $0, %rdi movq $60, %rax syscall
(gdb) break _start Breakpoint 1 at 0x400078: file divz.s, line 5. (gdb) run Starting program: /home/mwood/linux_amd64_adm/chap_07/divz Breakpoint 1, _start () at divz.s:5 5 movq $0, %rdx (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=19 (gdb) next 6 movq $19, %rax (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=0 (gdb) next 7 movq $0, %rcx (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=19 (gdb) next 8 divq %rcx (gdb) printf "rcx=%lld rdx=%lld rax=%lld\n", $rcx, $rdx, $rax rcx=0 rdx=0 rax=19 (gdb) next Program received signal SIGFPE, Arithmetic exception. _start () at divz.s:8 8 divq %rcx (gdb) next Program terminated with signal SIGFPE, Arithmetic exception. The program no longer exists.
Here, the CPU has thrown an exception interrupt. This suspends the execution of our program and returns control to Linux, which handles the event. Linux handles this event by terminating the program and dumping its core. Interrupts are a whole other thing that we will explore later.
As with multiplication, division requires that certain registers be used. This is where it gets fun. The nature of the machine really asserts itself: certain things have to be in certain registers for certain operations to work, because that's how the machine itself was designed.
It's also interesting how assembly programming is programming with both the CPU and the kernel at the lowest level: our program is at the mercy of the behavior of both.
What's with the q at the end of almost every command?
TODO
The stack!
TODO